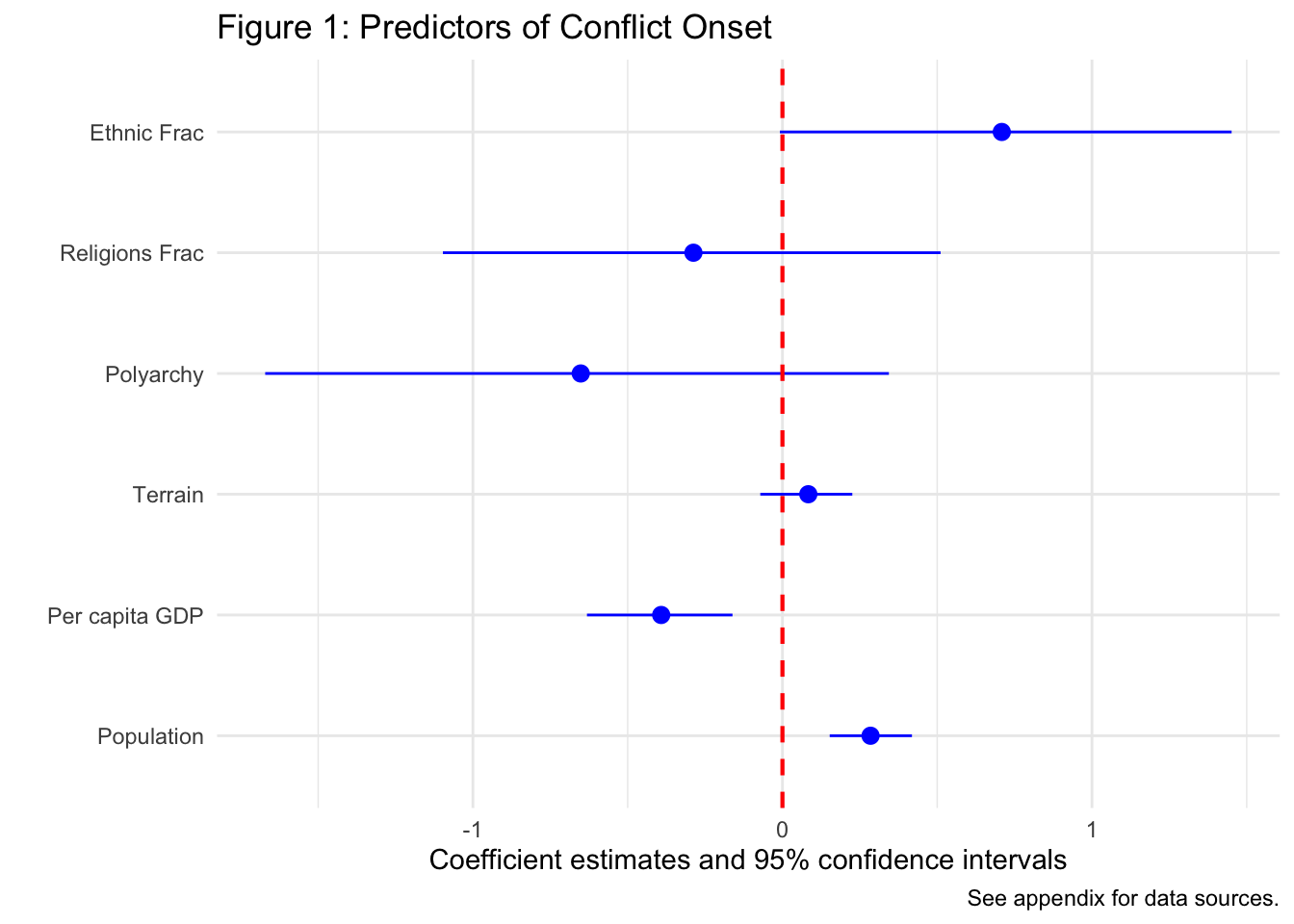
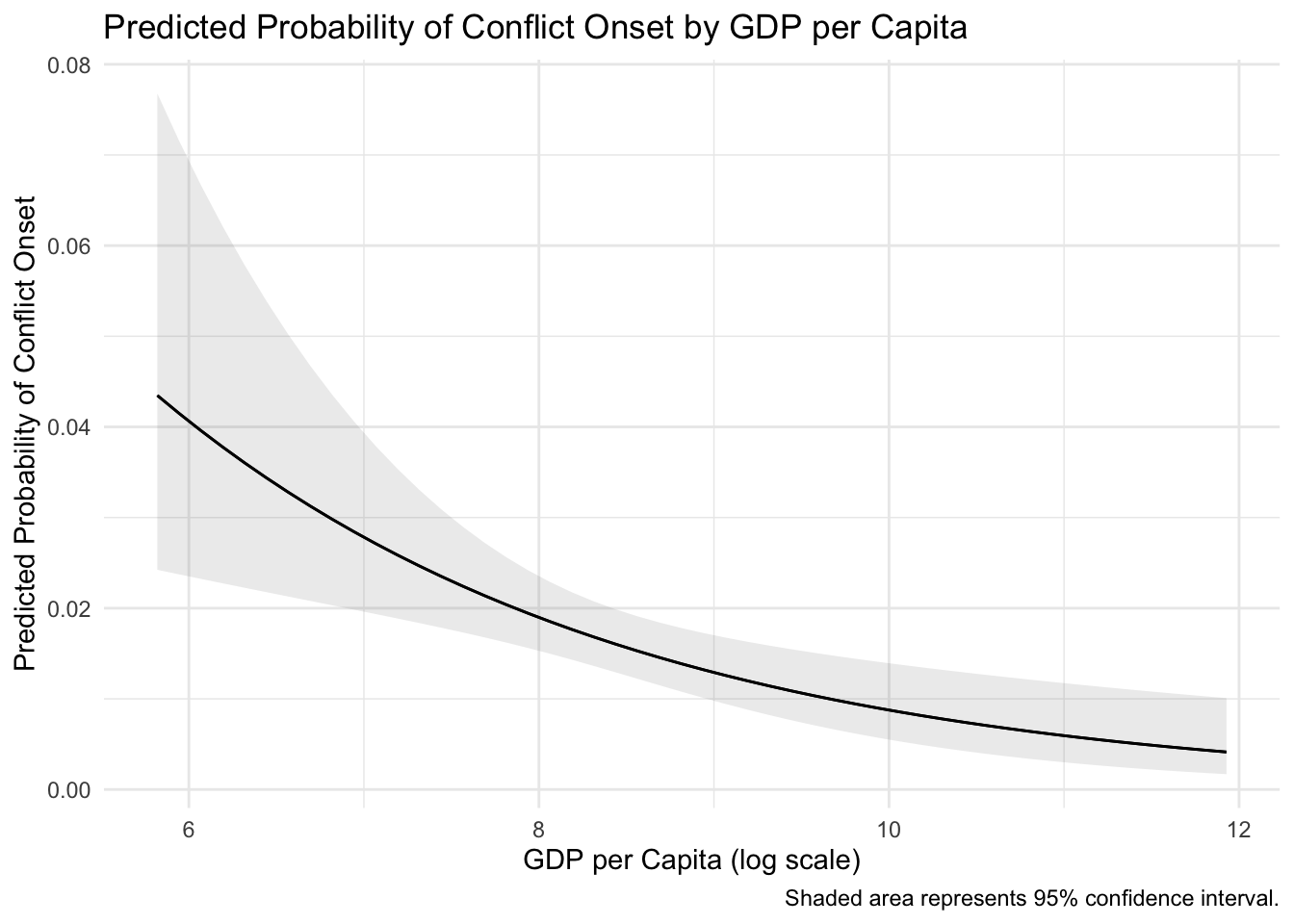
Rows: 7,624
Columns: 22
$ gwcode <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
$ gw_name <chr> "United States of America", "United States of America",…
$ microstate <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ year <dbl> 1946, 1947, 1948, 1949, 1950, 1951, 1952, 1953, 1954, 1…
$ ucdpongoing <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ ucdponset <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ maxintensity <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ conflict_ids <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ euds <dbl> 1.293985, 1.308359, 1.343539, 1.330836, 1.354015, 1.350…
$ aeuds <dbl> 0.4862558, 0.5006298, 0.5358093, 0.5231064, 0.5462858, …
$ polity2 <dbl> 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9…
$ v2x_polyarchy <dbl> 0.603, 0.607, 0.599, 0.580, 0.585, 0.611, 0.611, 0.612,…
$ ethfrac <dbl> 0.2226323, 0.2248701, 0.2271561, 0.2294918, 0.2318781, …
$ ethpol <dbl> 0.4152487, 0.4186156, 0.4220368, 0.4255134, 0.4290458, …
$ relfrac <dbl> 0.4980802, 0.5009111, 0.5037278, 0.5065309, 0.5093204, …
$ relpol <dbl> 0.7769888, 0.7770017, 0.7770303, 0.7770729, 0.7771274, …
$ wbgdp2011est <dbl> 28.539, 28.519, 28.545, 28.534, 28.572, 28.635, 28.669,…
$ wbpopest <dbl> 18.744, 18.756, 18.781, 18.804, 18.821, 18.832, 18.848,…
$ sdpest <dbl> 28.478, 28.456, 28.483, 28.469, 28.510, 28.576, 28.611,…
$ wbgdppc2011est <dbl> 9.794, 9.762, 9.764, 9.730, 9.752, 9.803, 9.821, 9.857,…
$ rugged <dbl> 1.073, 1.073, 1.073, 1.073, 1.073, 1.073, 1.073, 1.073,…
$ newlmtnest <dbl> 3.214868, 3.214868, 3.214868, 3.214868, 3.214868, 3.214…